Writing Liferay portlet to display a file in a way "tail -f" does
Don't know about you but I can't imagine debugging enterprise class applications without having "tail -f /path/to/log.file" running in dedicated console window. During development and testing phases (assuming work is done "in house") there is usually no problem with this approach as the whole team have access to servers' log files. This is not always the case with staging and production environments though. These days a lot of companies execute strong security policies which sometimes means that application is only accessible via HTTP. In such case, depending on how you SLA looks like, "log files provided on demand via e-mail or FTP" may not be an option.
Facing this kind of problem in recent Liferay based project, made me think about creating a portlet capable of displaying log files. Something like WWW based version of "tail -f". This is how Tailgate was born (for those of you looking for solution here is download page). The rest of this post will concentrate on explaining why it was not "a max 2h of coding" as I thought in the begging.
Tailgate portlet needs to dynamically show new lines as they are written to the file without reloading the whole portal page. Assuming one portlet instance is configured to display only one file, the solution appears to be straightforward and rather simple:
while page is displayed {While this is in general the whole functionality, there are a few things to consider on both front-end (client) and back-end (server) side.
browser sends AJAX request
server checks if there are new lines in given file
server responds with list of new lines
browser adds lines to appropriate DOM element
}
front-end
As far as front-end is concern there are 2 main things to consider:
Multiple instances on the same page
This is a bit tricky and requires good understanding of how portals work. When a portlet is developed it contains common code for all instances. So if multiple instance can be placed on the same portal page then the common code should be able to distinguish instances. This is even more important with AJAX requests.
In this case we have a common logic for sending and receiving AJAX requests and updating DOM model. However when portlet instance sends AJAX requests it needs to provide instance specific set of parameters as part of the URL. Also when response is received only DOM elements belonging to this particular instance need to be updated.
The common JavaScript code is provided in tailgate.js file. The portlet uses also jQuery timers module (jquery.timers.js) which provides high level abstraction of setTimeout and setInterval. These files are part of the portlet code. Including them in HTML page is done by adding
<header-portlet-javascript>/js/jquery.timers.js</header-portlet-javascript>
<header-portlet-javascript>/js/tailgate.js</header-portlet-javascript>
to WEB-INF/liferay-portlet.xml. This way Liferay will add appropriate links in HEAD section of HTML page and will do this only once regardless of how many portlet instances page contains.
The tailgate.js defines the Tailgate object and tailgateInstances map for holding information about Tailgate instances:
var tailgateInstances = new Array();
function Tailgate(lines, url) {
this.lines=lines
this.url=url
}
When portlet instance is rendered it takes care to prefix DOM element ids with it's namespace
<button id="<portlet:namespace />_start">Start</button>
<button id="<portlet:namespace />_stop">Stop</button>
...
<ul id="<portlet:namespace />list" class="tailgate">
, add itself to tailgateInstances map
<script type="text/javascript">
tailgateInstances["<portlet:namespace />"] =
new Tailgate(<%=prefs.getValue("lines","100")%>, "<liferay-portlet:resourceURL />");
and pass the namespace to called functions
jQuery("#<portlet:namespace />_start").click(function(){ startReading("<portlet:namespace />");
})
jQuery("#<portlet:namespace />_stop").click(function(){
stopReading("<portlet:namespace />");
})
</script>
Note that all functions in tailgate.js are designed to accept namespace as parameter. This way when called they can either get appropriate Tailgate instance from tailgateInstances map and then check for given property (for example url), or find and update DOM elements prefixed with this namespace.
Control the CPU and memory usage
Monitored file can change very fast (application could add few megabytes is just a second) therefore at first it seems to be very important to query back-end as often as possible. This however results in very high CPU usage. In fact going down below 10ms may force you to kill your browser in order to recover your system. Experimenting with different values I finally decided that refresh rate of one second is a reasonable compromise.
Another thing is memory. If lines are only added but never deleted then after a while the browser will be trying to display a tens of megabytes of HTML code. Therefore Tailgate is configured to only display last X lines. It renders each line as <li> element and when new line is added, a new <li> element is added to the parent <ul>. Then it checks the size of <ul> and if it's bigger than X, old lines are deleted from DOM model. Luckily jQuery comes with convenient methods so this is really easy to implement:
jQuery('#'+namespace+'list').append(data);
var maxLines = tailgateInstances[namespace].lines;
var lines = jQuery('#' + namespace + 'list li').length;
if (lines > maxLines) {
jQuery('#' + namespace + 'list li').slice(0, lines - maxLines).remove();
}
back-end
The line "server checks if there are new lines in given file" in the above pseudo algorithm is also way oversimplified.
The RandomAccessFile class provides the functionality to position at specific place in file and start reading. However creating a new instance on every request is not a very smart thing to do. Even if it is somehow cached per portlet instance, there still could be many instances monitoring the same file (in the future each may provide different filtering, highlighting, etc.) Also, depending on what file system is used (for example old versions of NFS), there may be some locking issues when multiple threads try to access the given file at the same time. Therefore it looks like the optimal solution would be to have one thread continuously reading the file and updating in memory buffers provided by specific instances. Here is the activity diagram:
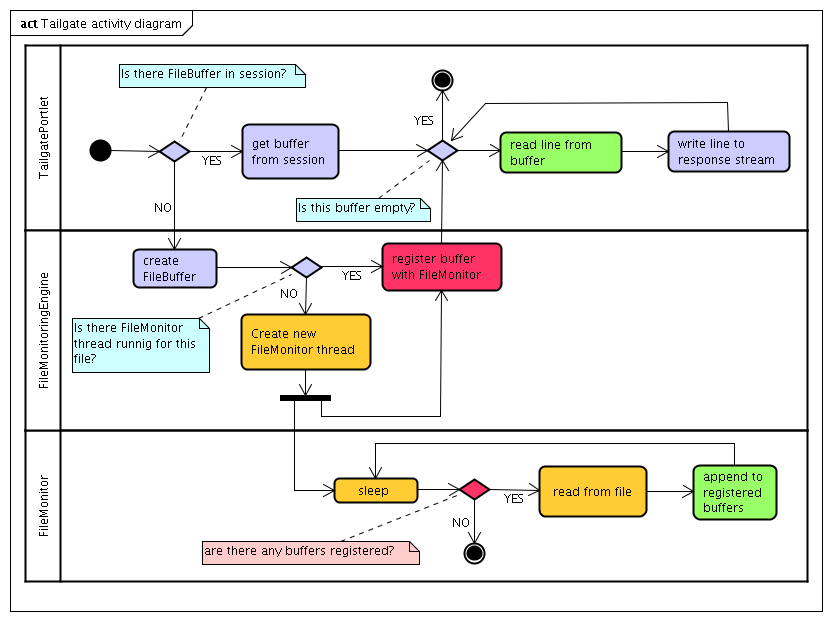
This looks simple enough but again there are a couple of things to think about:
synchronization
Since there are two thread operating on the same buffer (one writing and one reading) the buffer's read and write operations need to be synchronized. Otherwise a typical Memory Consistency Errors may occur.
buffer size
Buffers need to have fixed size in order to avoid memory leaks! Since the front-end also displays a limited amount of data, the same configuration parameter can be used to define both the number of lines displayed and buffered. Then every time a new line is added to the the oldest one is removed if buffer the size is reached:
public boolean addLine(final String line) {
boolean result;
synchronized (buffer) {
result = buffer.add(line);
if (buffer.size() > maxSize) {
buffer.remove();
}
}
return result;
}
when to stop reading
If you have carefully examined the activity diagram above you may have noticed that buffers are never unregistered. This is not an error, it is simply impossible to tell when a buffer is no longer needed. One may argue that user could send us appropriate message by clicking on something saying "I'm done watching, please stop the buffer!". My experience shows such approach is often misunderstood and misused (by that I mean used too often or not at all). So how can one prevent FileMonitor thread from running forever (it will run as long as there are buffers)? Let the garbage collector do it's job!
Buffers are stored in portlet sessions, so instead of relaying on user interaction, Tailgate relays on buffers being garbage collected once portlet session is closed. As you probably know an object becomes eligible for garbage collection when there are no hard references to it. Is this the case with buffers? As the diagram shows, buffers are referenced in 2 other places (marked in red) - FileMonitoringEngine needs to keep track of which buffer is assigned to which monitor and FileMonitor needs to maintain a list of buffers to write to. But here is the difference, in order to leverage the garbage collector's ability to determine buffers' reachability, both FileMonitoringEngine and FileMonitor use weak references. FileMonitoringEngine uses in fact standard WeakHashMap to store the mapping. FileMonitor only needs a Set of weak references but there is no WeakHashSet class. In JDK 6 there is a convenient "newSetFromMap(Map<E,Boolean> map)" method available in java.util.Collections class. In order to be compatible with JDK 5 the behavior of this the JDK 6 method had to be implemented as part of Tailgate portlet.
This way as soon as portlet session gets garbage collected there are no hard references to the buffer and it is collected as well. When all buffers are garbage collected the FileMonitor thread ends. The first request instantiating new buffer will start new FileMonitor thread which will again run as long as there is someone interested in receiving results.
Conclusion
I'm well aware I'm not writing anything really revealing here. But after spending some hours on Tailgate portlet I thought I would write about the problems and solutions. Hopefully you at least learned a little something from this experience. In case you are interested, Tailgate's source code is available at GitHub.